
The Importance of Code Separation and Why We Use a GIT Workflow for Managing Different Environments
It could be very debatable that in this day and age there are not that many companies, development shops, agencies or individual developers not using a strategy to keep different versions of the product (from now on I'm going to be referring to product rather than app, site, webpage to streamline the subject) isolated from each other depending on which point of the development process they are reflecting, but (and I'm quoting Mark Twain in this one) "truth is stranger than fiction...", and in this case truth refers to the reality of how the code for the product is managed.
Why is it important?
There are several reasons why having more than one environment to host your product is a good idea, there are ones that will make more sense to you depending on which role you take in software development (yes, even as an end-user you are still playing a role in that process), but one reason that will resonate with everyone involved is money. Yes, money in regards to cost.
Having only one environment dramatically increases the risk of downtime, and that downtime depending on the purpose of your product will likely result in decreased revenue, increased expenses/cost and a direct hit to your brand perception.
Scared yet? Well, not that I wanted to turn fear into a motivator but if it works...
If you want to be more technical about the reasons that you choose to have more than one environment and keep your code cleaner and more manageable, I can give you a list (and I love lists):
- Debugging is easier when you know what the actual differences are between an environment where a bug exists and one where it doesn't. Depending on whether the difference stems in code, data or configuration is a good starting point to eliminate possibilities and analyze what is introducing the unwanted behavior.
- If you have more than one developer involved in the product development and a separate team for testing purposes, each one gets their own sandbox to play with your product avoiding stepping into each other's toes. This is also true for when you have client involvement and they need to perform their own user acceptance testing.
- As a byproduct of the previous reason, it is easier to integrate (or remove) features into a stable codebase and minimize regression risk. Nobody likes it when something that was already working suddenly breaks.
- If you are using a type of Agile development along with a continuous integration strategy it will be easier to configure your target build points.
These are not all the reasons or the most important (that importance is a matter of perspective, remember?) but these are the ones that I think that most of you will relate to from the technical perspective.
Okay, I'm on board, how do I do it?
First and foremost, the one thing that you can't do without if you are trying to keep a sane head when managing code is to use a version control system (or VCS for short). There are plenty of tools out there for this purpose and the internet is filled with flame wars of which one is better so I won't go down that rabbit hole here and I will settle for using git to explain how I prefer to do it. You can always tailor the process to your specific product (or team) needs and kinks, and if that entails using a different tool, so be it.
Note: We are not going into a lot of detail into how we are going to do specific git commands, as that is not the purpose of this entry.
Cool, we are using git, but how?
A version control system allows us to keep track and history of what code changes have been made, when they were made, who made them, and which files (and specific lines of those files) were affected by the changes. From a project management perspective having that insight into the life of our product is a blessing if you pair it with a feature roadmap, sprint plan or backlog. From the release management experience it makes it easier to pack and ship the code to where it needs to be. From the development experience it makes it easier to rollback code if you make mistakes, to recreate features and use them as a starting point or to fork your work if you want to experiment without affecting all others involved.
A powerful feature of VCS is branching, and that's the base of the process that I use; This process is not entirely original, as it is heavily based on the git workflow devised and explained by Vincent Driessen in this blog entry (http://nvie.com/posts/a-successful-git-branching-model/), and is always a good go-to reference.
Branching Strategy
First look at this picture and let it sink in:
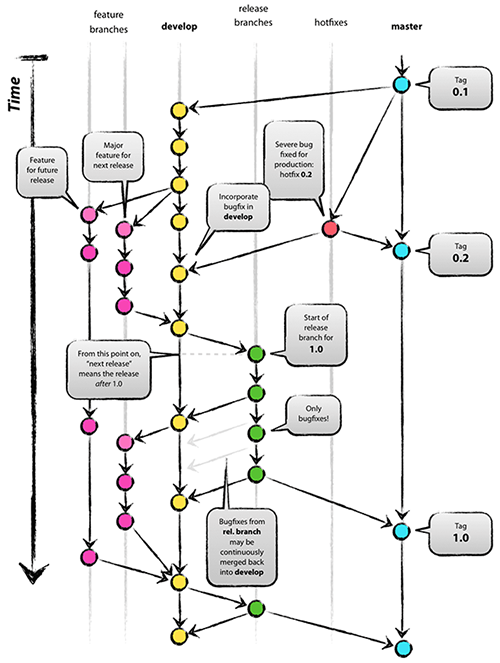
That model is inspired by existing models out there, don't dwell on that specific too much. Here are the main take-aways:
- Develop is a branch that is isolated from Master.
- Release branches are an offspring of develop.
- Features branches are integrated directly into develop, unless we have a hotfix, as that goes into Master and into Develop when it's approved for release.
Based on this I define three main branches that live indefinitely in my code repositories: Master, Test and Develop.
- Master is a reflection of the code that we have deployed to our *production* environment.
- Test is a reflection of the code that we have deployed to our *staging* environment.
- Develop is a reflection of the code that we have deployed to our *develop* environment or sandbox.
- Using remotes as backups (not its primary purpose, but added bonus)
So, we went from talking about branches to environments and there's a perfectly good reason for that: We are reducing the parity to how many environments we can have at any specific point in time to 1:1 with our main code branches. Is it possible to have more than those three? absolutely, but remember that if you keep increasing the number of environments that you are managing there is a point in which it becomes more work to do so compared to the marginal benefits that you are getting out of it (law of diminishing returns), so for simplicity I'd suggest to stick to those three until you are comfortable with the process.
What specific uses does each environment have?
Develop is the main branch where the source code for the latest development changes live. Calling this one the integration branch is not too farfetched. Specific feature testing by someone other than the developer happens in this environment, data is a sanitized version of production but it is still manipulable for specific tests.
Once the changes in the develop branch reach a stable point (or you have a scheduled staging release) the approved changes from the feature testing results should be merged back into the Test branch and tagged with a release number that will go into the Staging environment.
The Staging environment has a fresher version of the production data (still sanitized if there are concerns about sensitive data) but it is advised to not perform data manipulation that wouldn't happen in a regular way on the production version of the product. The main purpose of the Staging environment is to serve as a dress rehearsal of sorts of how the updated code will affect the production version (hence the name, Staging). User acceptance testing can happen in this environment as well as a more complete regression test that will cover more than what the specific feature testing did.
If changes for new features are approved on the Staging environment and no big showstopper bugs are discovered by the regression test then we can merge the changes back into the master branch, tag them and prepare a production release.
Supporting branches
That covers a traditional release process from develop to staging to production, but, what about not so traditional situations? (which in reality are more frequent that anyone would care to admit). For that type of situations we have supporting branches that also fit within our model:
- Feature branches
- Release branches
- Hotfix branches
Can these supporting branches have their own environments? yes, they can, but in reality it is not as practical to give them their own environment because they are short lived.
Feature branches (or sometimes called topic branches) are what the individual developers use to create new features (or functionality updates) for an upcoming release. This gives the developer the ability and the decision power to integrate these changes into the develop branch for the current or a future release without affecting the existing codebase if the change is decided to be dropped. In essence a feature branch should exist as long as the feature is considered to be in development, when that feature is merged back into Develop that is a good point when that branch can be eliminated from the local development environment and the remote that hosts the code repository.
Release branches support preparation for stage or production releases, they can branch off from develop or test depending on what the release target is (branch off develop if you are preparing a stage release, branch off test if you are preparing a production release). In which instance is a release branch necessary? In an ideal world you will always move code from environment to the next as is, without taking anything out or adding anything extra but the sad reality of the cruel software development world is very different from this. Sometimes a feature is not as complete as you thought it was and it doesn't meet acceptance criteria, or it could be that it needs some extra code commits to finally reach its final form, or it introduces a nasty bug that would not be so easily fixed or simply it was decided that it was no longer needed, in any of those cases we need to remove it from our release and a release branch can helps us do that either by reverting the code commits specific to the feature that is not needed or by cherry-picking additional code that will improve the current state of the feature. That's what release branches are used for in this model.
And finally, hotfix branches, usually not pretty but often needed. They branch off from master but must be merged back into develop and master itself. These are used to address pressing issues with the production code, usually security concerns or very badly broken functionality that was not caught by the previous testing (it can happen). If a hotfix is needed in a specific point in which the Staging and production environment have the same codebase (after a stage release, but before the next one) we can use the Staging environment to deploy the hotfix and test it before we do the production release for it. Another strategy to avoid 'Cowboying' the hotfix release in case that staging has a slightly more advanced version of the code is to generate a shortlived copy of the production environment somewhere else and deploy the hotfix there first. This environment should be destroyed after the hotfix is confirmed as working and deployed to production (less overhead to manage, it already served its purpose).
Is this process perfect?
Far from it, but it gives you an starting point to keep a cleaner code base. My advice would be to understand it and see how it could apply to your existing workflow, take what works for it and tweak what doesn't (at least in the way that it is suggested) and make it your own.
Processes need to be treated as a living, evolving thing. Circumstances and context for what you are doing change all the time so it is almost expected that your processes would adapt to these changes. Just don't let it overwhelm you, its purpose is to give you more time to focus on other more important things not to be a constant worry in the back of your head.












